数据库读写分离Master-Slave
一个平台或系统随着时间的推移和用户量的增多,数据库操作往往会变慢,这时我们需要一些有效的优化手段来提高数据库的执行速度;如SQL优化、表结构优化、索引优化、引擎优化和读写分离优化等手段。
1、SQL优化(简单列几点):
尽量避免用SELECT*;只查询一条记录时使用limit1;使用连接查询代替子查询;尽量使用一些能通过索引查询的关键字。
2、表结构优化:
尽量使用数字类型字段,提高对比效率;长度不变且对查询速度要求高的数据可以考虑使用char,否则使用varchar;表中字段过多时可以适当的进行垂直分割,将部分字段移动到另一张表;表中数据量大可以适当的进行水平分割,将部分数据移动到另一张表。
3、索引优化:
对查询频率高的字段适当建立索引,提高效率。(在经常用到的字段上适合建立索引)
4、引擎优化:
选择合适的引擎提高数据库性能,如InnoDB和MyISAM,InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定。基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持已经外部键等高级数据库功能。InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。 MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比较低,也可以使用。MEMORY:所有的数据都在内存中,数据的处理速度快,但是安全性不高。如果需要很快的读写速度,对数据的安全性要求较低,可以选择MEMOEY。它对表的大小有要求,不能建立太大的表。所以,这类数据库只使用在相对较小的数据库表。注意:同一个数据库也可以使用多种存储引擎的表,如果一个表要求比较高的事务处理,可以选择InnoDB;这个数据库中可以将查询要求比较高的表选择MyISAM存储;如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
5、读写分离优化:
随着用户量的增多,数据库操作往往会成为一个系统的瓶颈所在,但一般的系统“读”的压力远远大于“写”,So我们可以通过实现数据库读写分离-主从复制来提高系统的性能。
主从设计思路:
通过设置主从数据库实现读写分离,主数据库负责“写操作”,从数据库负责“读操作”,根据压力情况,从数据库可以部署多个提高“读”的速度,借此来提高系统总体的性能。当然,我们可以根据项目等需要配置多个从库。
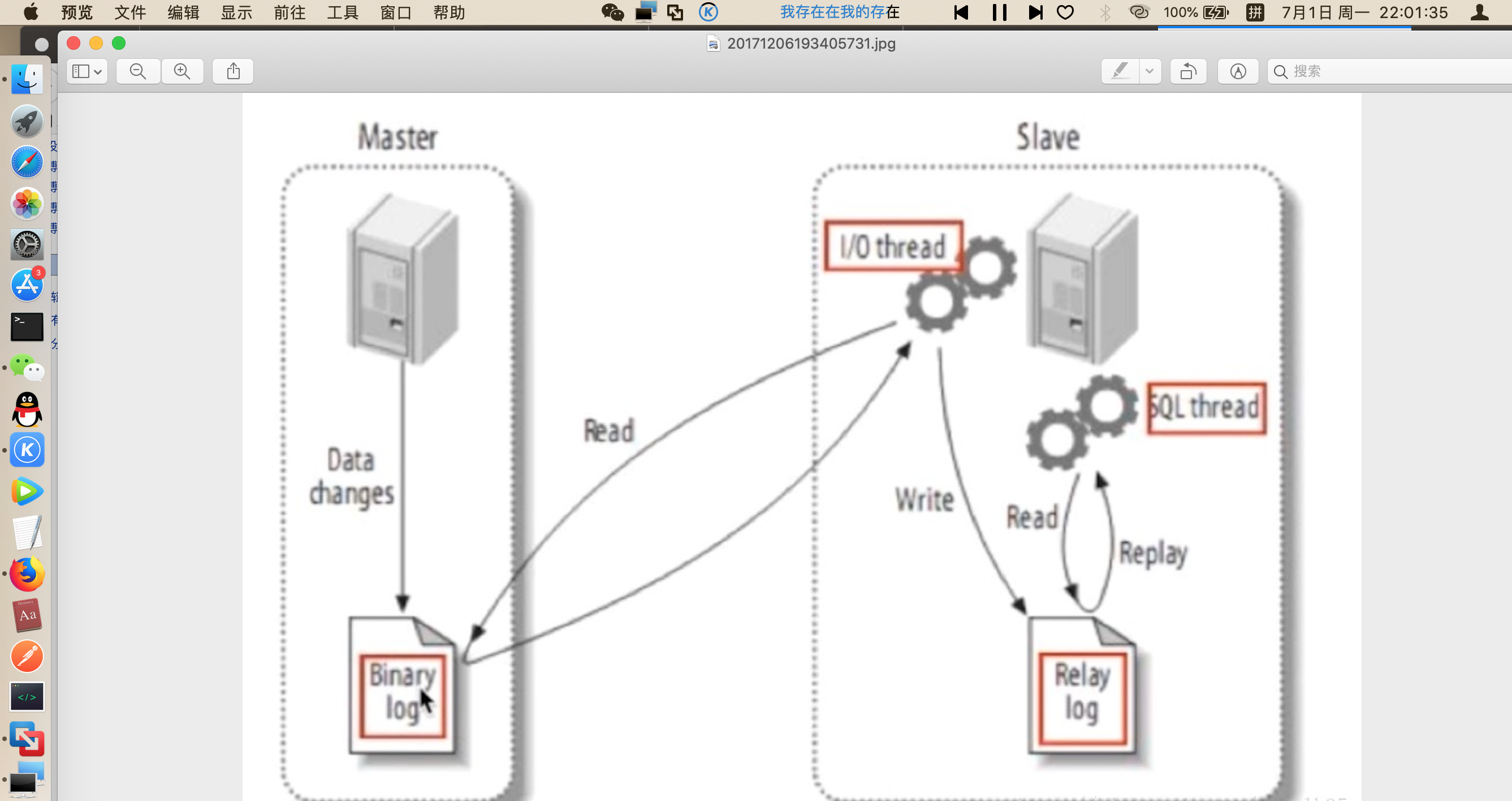
如上图所示,读写分离的实现,主要是解决主从数据库数据同步的问题,在主数据库写入数据后要保证从数据库的数据也要更新。主服务器master记录数据库操作日志到Binary log,从服务器开启i/o线程将二进制日志记录的操作同步到relay log(存在从服务器的缓存中),另外sql线程将relay log日志记录的操作在从服务器执行。
Master-Slave具体步骤
准备工作,在这之前需要准备两个服务器,分别在上面安装Mysql数据库,一个作为Master,另外一个是Slave,当然需要多个从库可以自己搞多个Slave。如下图:
两个虚拟机服务器:

分别安装Mysql数据库:

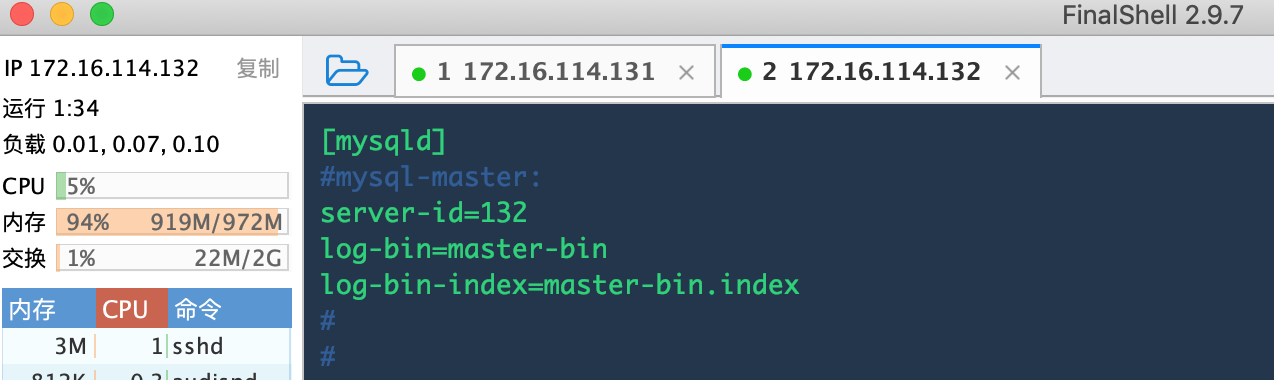
1.主mysql数据库配置文件修改
[root@tjt03 ~]# vim /etc/my.cnf
在主服务器master上配置开启Binary log,主要是在[mysqld]下面添加:
server-id=132log-bin=master-bin //[必须]启用二进制日志log-bin-index=master-bin.index //[必须]服务器唯一ID,默认是1,一般取IP最后一段
配置修改好后重主库Mysql:
[root@tjt03 ~]# sudo service mysqld stopStopping mysqld (via systemctl): [ OK ][root@tjt03 ~]# sudo service mysqld startStarting mysqld (via systemctl): [ OK ][root@tjt03 ~]#
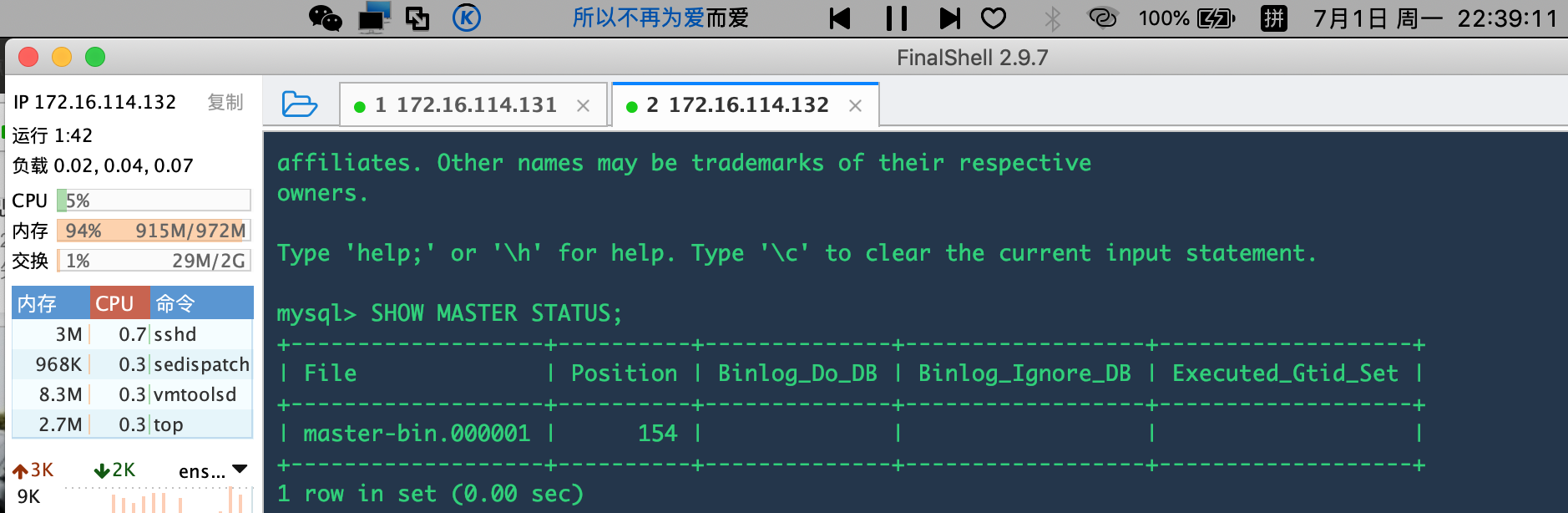
在主数据库检查配置效果:
mysql> SHOW MASTER STATUS;
可以看到下图表示配置没问题,这里面的File名:master-bin.000001 我们接下来在从数据库的配置会使用:
2.从mysql数据库配置文件修改
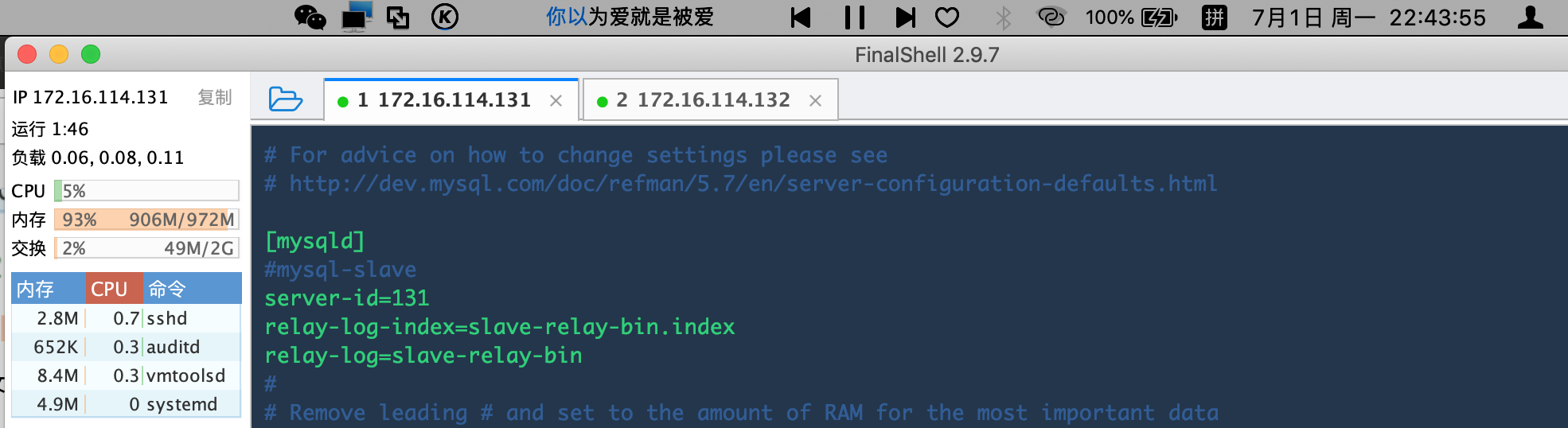
[root@tjt02 mysql]# vim /etc/my.cnf
在从服务器slave上的[mysqld]下面添加:
server-id=131 //这里面的server-id 一定要和主库的不同relay-log-index=slave-relay-bin.indexrelay-log=slave-relay-bin
配置修改好后重从库Mysql:
[root@tjt02 mysql]# service mysqld stopStopping mysqld (via systemctl): [ OK ][root@tjt02 mysql]# service mysqld startStarting mysqld (via systemctl): [ OK ][root@tjt02 mysql]#
3、配置两个数据库的关联
首先我们先建立一个操作主从同步的数据库用户,切换到主数据库执行:
mysql> GRANT REPLICATION SLAVE ON *.* to 'tjt'@'%' identified by 'TANjintao@520';
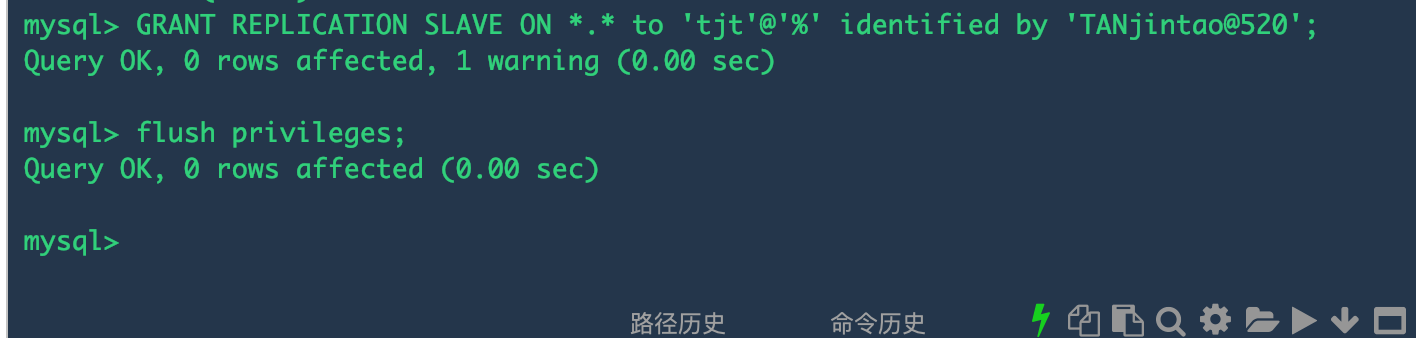
这个配置的含义就是创建了一个数据库用户tjt,密码是TANjintao@520, 在从服务器使用tjt这个账号和主服务器连接的时候,就赋予其REPLICATION SLAVE的权限, *.* 表面这个权限是针对主库的所有表的,“%”表示所有客户端都可能连,只要帐号,密码正确,此处可用具体客户端IP代替,如192.168.145.226,加强安全。
进入从数据库执行授权Slave:
mysql> change master to master_host='172.16.114.132',master_port=3306,master_user='tjt',master_password='TANjintao@520',master_log_file='master-bin.000001',master_log_pos=0;
上述步骤执行完毕后执行start slave启动配置:
mysql> start slave;

停止主从同步的命令为:
mysql> stop slave;
查看状态命令,\G表示换行查看:
mysql> show slave status \G;*************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.16.114.132 Master_User: tjt Master_Port: 3306 Connect_Retry: 60 Master_Log_File: master-bin.000001 Read_Master_Log_Pos: 870 Relay_Log_File: slave-relay-bin.000002 Relay_Log_Pos: 1085 Relay_Master_Log_File: master-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB:
可以看到状态如下:
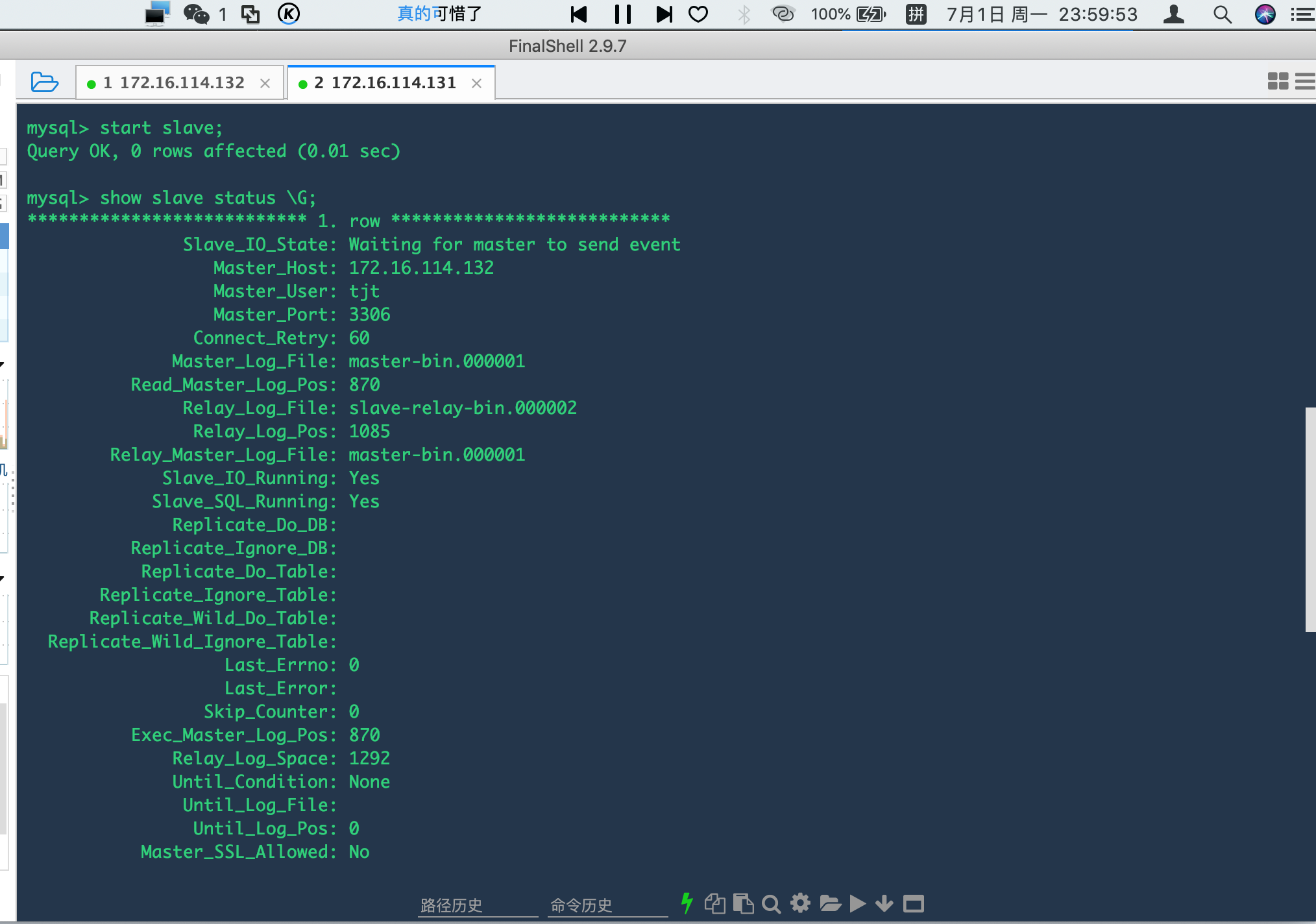
这里看到从数据库已经在等待主库的消息了,接下来在主库的操作,在从库都会执行了。我们可以主库负责写,从库负责读,达到读写分离的效果。
注:Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
简单测试
在主数据库中创建一个新的数据库:
mysql> create database tjt0702;

在从数据库查看数据库:
mysql> show databases;
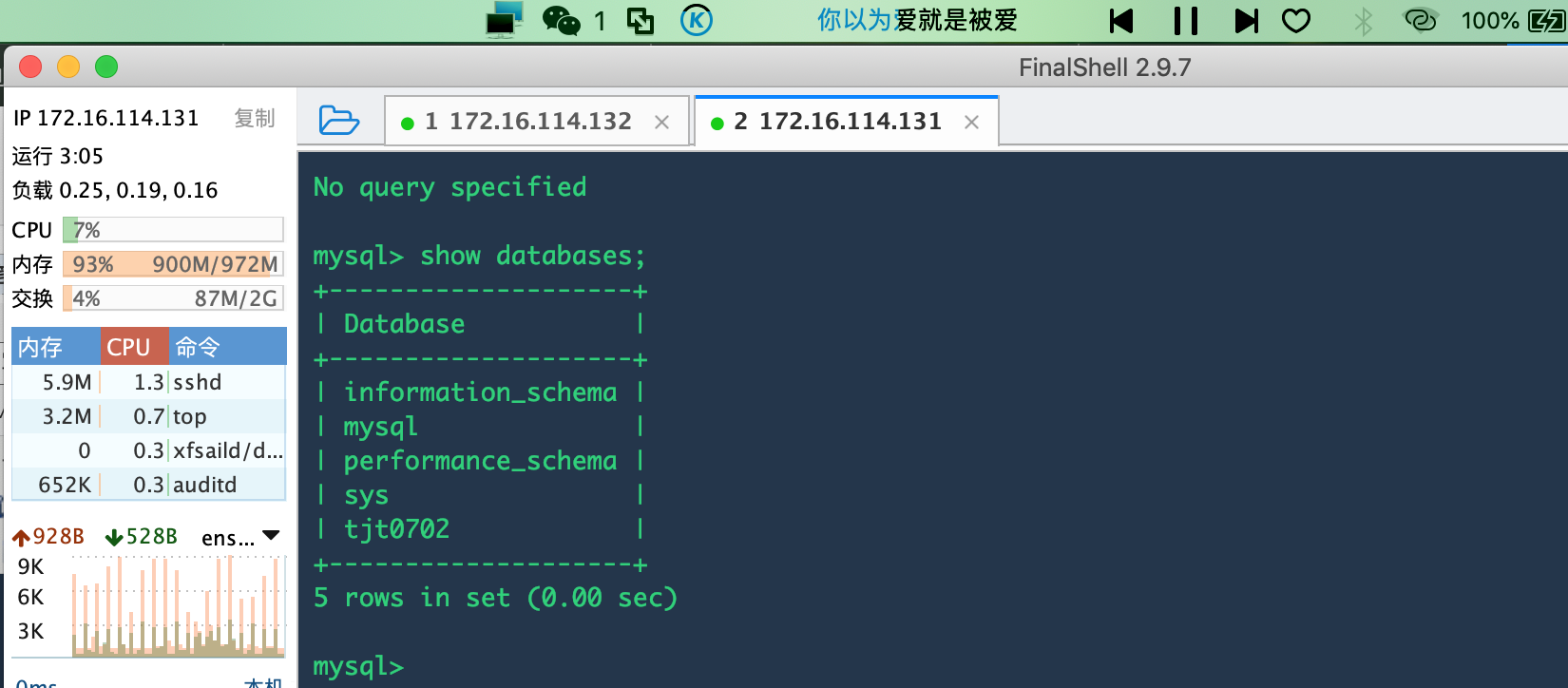
到这里,数据库的主从复制Master-Slave已经OK了。
代码层面实现读写分离
假设我们使用的是主流的SpringBoot框架开发的web项目,实现数据库读写分离如下。
配置了一个从库Slave:
配置了两个从库Slave:
配置两个数据库的关联
配置两个数据库的关联